Traducción Automática Neuronal: funcionamiento, Seq2Seq y transformers.
Traducción a Español de un artículo de Azad Yaşar, explicando los nuevos modelos Seq2Seq de Traducción Automática Neuronal, capaces de mapear y trazar relaciones entre 2 idiomas en base a un corpus paralelo.
 28 junio, 2021 Mapa de atencion de una Traducción Automática Neuronal
28 junio, 2021 Mapa de atencion de una Traducción Automática NeuronalTraducción realizada por Jose, traductor experto en tecnologías de Traducción Automática Neuronal.
Original text written by Azad Yaşar and published in TowardsDataScience
***
INDICE
Introducción
Recientemente, tuve la oportunidad de trabajar con sistemas de Traducción Automática Neuronal (NMT) para un proyecto trimestral. Fue divertido jugar con los modelos más avanzados. Así que decidí escribir mi primer artículo en Medium sobre ello, para ayudar a la gente interesada en NMT, o más en general en Aprendizaje Automático + Procesamiento del Lenguaje Natural, y que puedan entrenar sus propios modelos personalizados.
Intentaré cubrir los siguientes temas:
- ¿Qué es la Traducción Automática (MT)? ¿Cómo funciona la NMT?
- ¿Cómo funciona la arquitectura Seq2Seq (secuencia a secuencia)? ¿Qué problemas puede resolver?
- Modelos NMT (Seq2Seq) de última generación, principalmente RNNs con mecanismo de atención y Transformer (mecanismo de atención y la auto-atención).
- ¿Qué es la codificación por pares de bytes (BPE)? ¿Cómo nos ayuda en la tarea de traducción?
- ¿Cómo evaluar los sistemas NMT? Interpretabilidad con el mapa de atención.
- Por último, mostraré cómo puedes aprovechar el repositorio adjunto para entrenar tus propios modelos de MT.
¿Qué es la Traducción Automática? ¿Cómo funciona la NMT?
Definamos primero el problema que intentamos resolver con la NMT. Podemos considerar la tarea de Traducción Automática como una modelización de la probabilidad condicional P(y|x), donde x e y se refieren a la frase de entrada y de salida, respectivamente. Lo que intentamos es, para una frase x en el idioma X, encontrar la mejor frase y en otra lengua Y. Podemos escribir formalmente este objetivo como en la Ecuación 1, es decir, queremos encontrar la frase de salida y que maximice la probabilidad condicional P(y|x). Podemos reescribir este objetivo utilizando la regla de Bayes como P(x|y)P(y).
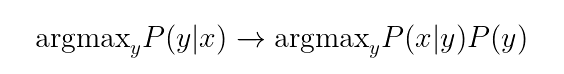
En este caso, P(x|y) modela el modelo de traducción, es decir, cómo se traducen las palabras y las frases, y P(y) modela el modelo de la lengua de destino, que es Y. Podemos considerar que esta última probabilidad da una puntuación de fluidez a la frase de salida, por ejemplo, P(«estoy estudiando») > P(«estoy estudiando»). Existen métodos que podemos emplear para crear un modelo lingüístico P(y). La cuestión más difícil es cómo construir el modelo de traducción P(x|y). Podemos utilizar un corpus de traducción con muchos pares de frases. Existen métodos estadísticos de traducción automática que intentan encontrar el modelo de traducción. Pero es un problema sutil. Una lengua en sí misma es compleja y ambigua, pero intentamos expresar el significado de una frase en otra lengua, lo que puede ser complicado incluso para frases sencillas. Consideremos el siguiente ejemplo en turco: «Yarın çalışacağım», que se traduce como «Estudiaré mañana». La figura 1 ilustra la alineación entre estas dos frases.
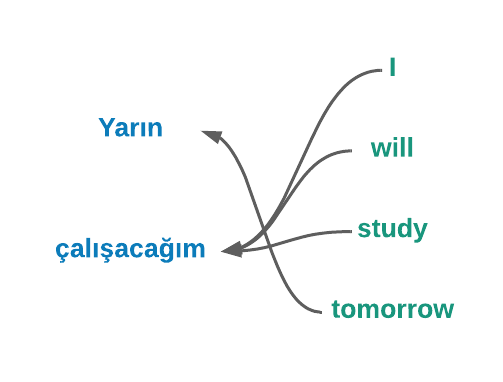
El turco es una lengua aglutinante. Así, una palabra puede estar compuesta por varios sufijos que afectan significativamente al significado semántico de la frase. En este ejemplo, la palabra «çalışacağım» puede dividirse en los siguientes tokens: «çalış+acak+ım» que, por simple correspondencia entre palabras, hacen referencia a estudio, voluntad y yo, respectivamente. Como puede verse, es bastante difícil deducir la relación entre estas dos frases simples. Ahora imagine qué pasaría si entraran en juego lenguas más complejas como el chino.
Existen métodos de traducción automática estadística que intentan trazar la relación entre las lenguas. Pero este post pretende explicar cómo la Traducción Automática Neuronal aborda este problema. Spoiler: la NMT modela directamente la P(y|x).
Traducción Automática Neuronal y Secuencia a Secuencia
En 2014, Sutskever et al. propusieron la arquitectura secuencia-a-secuencia para aplicaciones de Procesamiento del Lenguaje Natural [1]. La arquitectura original consiste en un par de Redes Neuronales Recurrentes: (1) la primera RNN se encarga de codificar la secuencia de entrada llamada codificador, (2) la segunda RNN toma el vector codificado y genera la secuencia objetivo. Nótese que nos referimos a la entrada y a la salida como secuencias en lugar de frases. Es para evitar que nos limitemos sólo a los problemas relacionados con el lenguaje natural. La figura 2 muestra la arquitectura correspondiente, en la que la secuencia de entrada «A B C» se convierte en «W X Y Z«.

Podemos utilizar la arquitectura secuencia a secuencia en muchos escenarios, por ejemplo:
- Resumir: Dado un pasaje largo (por ejemplo, una noticia, un capítulo de un libro, un artículo), generar su resumen.
- Traducción Automática: Dada una frase de una lengua de origen, generar la frase correspondiente en otra lengua de destino.
- Responder a una pregunta: Dado un texto y una pregunta sobre dicho texto , generar una respuesta correcta.
- Corrección de errores gramaticales: Dada una frase posiblemente con errores gramaticales u ortográficos, generar la frase correcta corrigiendo dichos errores.
- La lista puede seguir y seguir. Se pueden proponer fácilmente otras áreas de aplicación interesantes, por ejemplo, dado un zumbido → generar música, generar código (los programadores no tenemos por qué preocuparnos; el modelo genera más errores que nosotros mismos :P). Cualquier cosa que se pueda plantear como un problema de secuencia a secuencia, se puede modelar con esta arquitectura.
No voy a profundizar mucho al hablar de Redes Neuronales Recurrentes porque hay un montón de recursos que explican bien cómo funcionan. Pero, en resumen, procesan la secuencia de entrada token a token. «¿Por qué no procesan todos los tokens a la vez? Continuemos la discusión con los lenguajes naturales. Es evidente que el orden es importante en una frase. Las Redes Neuronales Recurrentes nos permiten modelar entradas ordenadas, por ejemplo, series temporales. Consideremos la siguiente función: h¹=f(x¹, h⁰) donde x¹ es la primera palabra y h⁰ es el estado oculto inicial. Al procesar la siguiente palabra x², tenemos h²=f(x², h¹). Tener en cuenta el estado oculto anterior h¹ nos permite utilizar la información pasada mientras modelamos la palabra actual. ¿Se ha dado cuenta de lo que estamos pasando al descodificador? Si la frase de entrada consta de 6 palabras, entonces estamos pasando el sexto estado oculto h⁶. Hay otros enfoques para mejorar esta representación, como las RNN Bidireccionales, la Memoria a Largo Plazo y las Unidades Recurrentes con Puerta. Pero quedémonos con el caso más sencillo. El decodificador tiene ahora el vector codificado que puede utilizar como su vector oculto inicial h⁰ y empezar a decodificar la frase de salida. Puede que no esté claro al principio, pero hay un cuello de botella en la arquitectura. Supongamos que utilizamos un vector de 128 dimensiones para representar las unidades ocultas. Eso significa que el vector codificado que se pasa al descodificador es también de 128 dimensiones, véase la figura 3. Consideremos ahora dos frases de entrada, una con unas pocas palabras sencillas y otra con palabras complejas y subcláusulas. ¿Es justo codificar estas dos frases con el mismo número de dimensiones? Los resultados de la evaluación dicen que no. Entonces, ¿cómo podemos superar este problema?

Figura 3: Encoder y Decoder RNN
Mecanismo de Atención
Como ya se ha dicho, utilizar un vector de longitud fija supone un cuello de botella en el modelo. No hay mucho espacio para que el modelo pase información del codificador al decodificador y, al mismo tiempo, la retropropagación no puede pasar completamente los gradientes hacia atrás. Para aliviar esto, Bahdanau et al. emplean el Mecanismo de Atención para que el decodificador pueda centrarse en los tokens de origen que son relevantes, mientras genera el siguiente token [2]. Expliquemos el Mecanismo de Atención con una ilustración (figura 4). Del ejemplo anterior, tenemos la siguiente frase de entrada «Yarın çalışacağım». El modelo ya ha generado los tres primeros tokens: «Voy a estudiar», ahora esperamos que genere «mañana». Utilizamos la última representación oculta u³ del descodificador junto con la representación oculta de los tokens de entrada [h¹, h²] y calculamos los productos de puntos entre ellos. ¿Qué es un producto puntual, después de todo? Nos dice hasta qué punto dos vectores apuntan en la misma dirección → hasta qué punto están correlacionados → hasta qué punto los tokens correspondientes son relevantes entre sí. En este ejemplo muy concreto, la palabra mañana coincide exactamente con el token de entrada Yarın, por lo que obtenemos una puntuación de producto de puntos más alta. Estas puntuaciones no están normalizadas, así que las pasamos por una función softmax para obtener una distribución de probabilidad final sobre los tokens de entrada. Usamos la distribución de probabilidad para obtener una suma ponderada de los tokens de entrada. En este caso, el token más relevante era Yarın; porque tiene una puntuación relativamente más alta en comparación con el segundo token de entrada. Entonces, en lugar de usar directamente la representación oculta del decodificador, usamos esta suma ponderada para predecir el siguiente token.

El Mecanismo de Atención mejora significativamente el rendimiento del modelo en muchas aplicaciones de secuencia a secuencia. Pero la gente no se ha quedado ahí y se han propuesto enfoques más potentes.
El Transformer
Vaswani et al., habiendo visto el efecto del Mecanismo de Atención, propusieron este modelo para la Traducción Automática Neuronal [3] (aunque puede aplicarse a otras tareas seq2seq). El Transformer, a alto nivel, es el mismo que el modelo anterior de secuencia a secuencia con un par codificador-decodificador. El codificador codifica la secuencia de entrada y el decodificador genera la secuencia de salida. Sin embargo, encontraron una forma de utilizar el Mecanismo de Atención dentro del codificador, llamado Mecanismo de Autoatención. Hemos visto que el Mecanismo de Atención nos ayuda a pasar la información eficazmente entre el par codificador-decodificador en ambas direcciones. La Autoatención, además, ayuda al codificador a codificar la secuencia de forma mucho más eficiente.
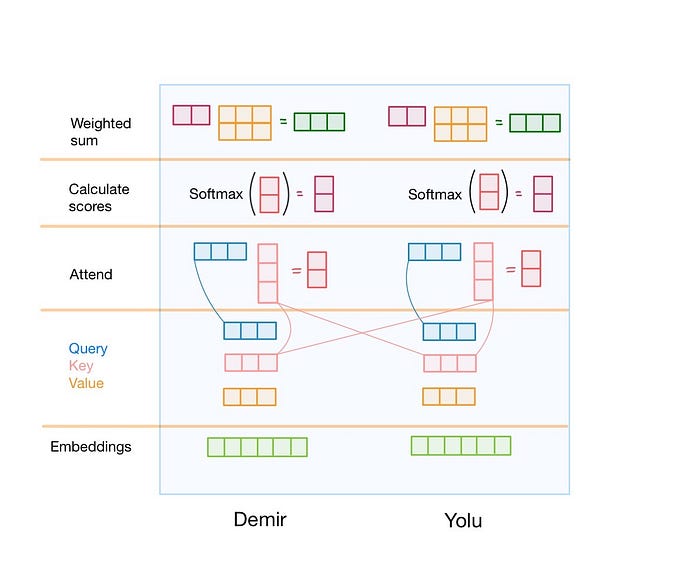
La figura 5 ilustra los pasos necesarios para el mecanismo de autoatención. Expliquemos lo que ocurre en realidad:
- Tenemos la secuencia de entrada Demir Yolu, obtenemos las incrustaciones para los tokens Demir y Yolu. Proyectamos estas incrustaciones en 3 espacios distintos: consulta, clave y valor. (Proyectar es la forma elegante de decir multiplicar con una matriz)
- Tomamos el vector de consulta de un token específico y calculamos el producto punto entre este vector de consulta y todos los vectores clave. Esto se hace para los vectores de consulta de todos los tokens de la secuencia de entrada. La gente se refiere a este procedimiento como «El vector de consulta de un token atiende a otros tokens». ¿Ha notado algo raro? No necesitamos el estado oculto del token anterior para calcular el estado oculto del token actual. Eso significa que podemos ejecutar la Autoatención en paralelo para todos los tokens de la secuencia de entrada. Esto acelera significativamente el tiempo de entrenamiento y de inferencia.
- Ahora tenemos las puntuaciones brutas entre cada par de tokens en la secuencia de entrada. Los pasamos por la capa softmax para normalizar las puntuaciones.
- La salida de la capa softmax es una distribución de probabilidad sobre los tokens de entrada. Utilizamos estas puntuaciones normalizadas para obtener una suma ponderada de los vectores de valores (calculados individualmente para cada token).
Para hacerlo más concreto, supongamos que el token en la posición i está estrechamente relacionado con otro token en la posición j. Esperamos que el producto punto entre el vector de consulta del token i y el vector clave del token j sea mayor en comparación con otros tokens irrelevantes. Esto significa que, más adelante, en los pasos siguientes, el token j tendrá más impacto al construir la representación de salida del token i. Podemos llamar a las representaciones de salida incrustaciones de palabras contextuales. Porque las representaciones se crean con respecto al contexto. Lo ideal sería que la incrustación contextual de la palabra clave en las dos frases siguientes fuera diferente: (1) Rompí la llave al abrir la puerta. (2) El punto clave del discurso no estaba claro.
Codificación de pares de bytes
Antes de entrar de lleno en la parte de la traducción, creo que sería beneficioso hablar del enfoque BPE. Uno de los mayores problemas a los que se enfrentan los sistemas NMT es la falta de vocabulario (OOV). Sabemos que utilizamos una incrustación para cada palabra del vocabulario. Supongamos que utilizamos vectores de 512 dimensiones para incrustar las palabras turcas. En realidad, los vectores de 512 dimensiones no son tan grandes en comparación con los modelos más avanzados. Como hemos dicho antes, el turco es aglutinante y morfológicamente bastante complejo. Es bastante fácil derivar nuevas palabras introduciendo sufijos. Consideremos la siguiente palabra «gel», que significa «venir». Podemos generar fácilmente las siguientes palabras «gel+eceğ+im» que significa «vendré». Si introdujéramos una palabra nueva cada vez que se añade un sufijo a una palabra existente, el tamaño del vocabulario superaría fácilmente los 300K. Supongamos que utilizamos el formato de coma flotante de precisión simple para almacenar los vectores. Esto significa que la matriz de incrustación de palabras requiere por sí sola 300.000 * 512 * 4 bytes, es decir, unos 600 MB de espacio de almacenamiento, por no hablar del resto del modelo. El método BPE aprende estos sufijos y morfemas de forma no supervisada con la ayuda de un gran corpus de texto. El método BPE se propuso originalmente como un algoritmo de compresión. Pero Sennrich et al. tuvieron la brillante idea de aplicarlo para superar el problema del OOV [4]. Con BPE, la palabra «geleceğim» sería idealmente tokenizada en «gel eceğ im».
Traducción con un modelo autorregresivo
Hasta ahora, hemos visto los entresijos de los modelos secuencia a secuencia. Pero, ¿Cómo se realiza una traducción real? Utilicemos el ejemplo de traducción representado en la figura 6. Tenemos la secuencia de entrada «dışarı çıkmak için hava soğuk değil mi?». He fusionado los tokens BPE correspondientes para simplificar las diapositivas. Volviendo al ejemplo, codificamos la secuencia de entrada con el codificador Transformer. Una vez que hemos terminado, alimentamos el decodificador Transformer con un token artificial <start> para que genere los siguientes tokens. El decodificador utiliza el token inicial junto con los tokens de la secuencia de entrada para empezar a generar los tokens de destino. El primer token que genera es «eso». Esta vez utilizamos la salida del decodificador, que es «eso«, y lo alimentamos con los tokens anteriores y esperamos que genere el siguiente token. Este procedimiento continúa hasta que el modelo genera otro token artificial llamado <eos> (que significa fin de frase) para indicar que la traducción ha terminado.
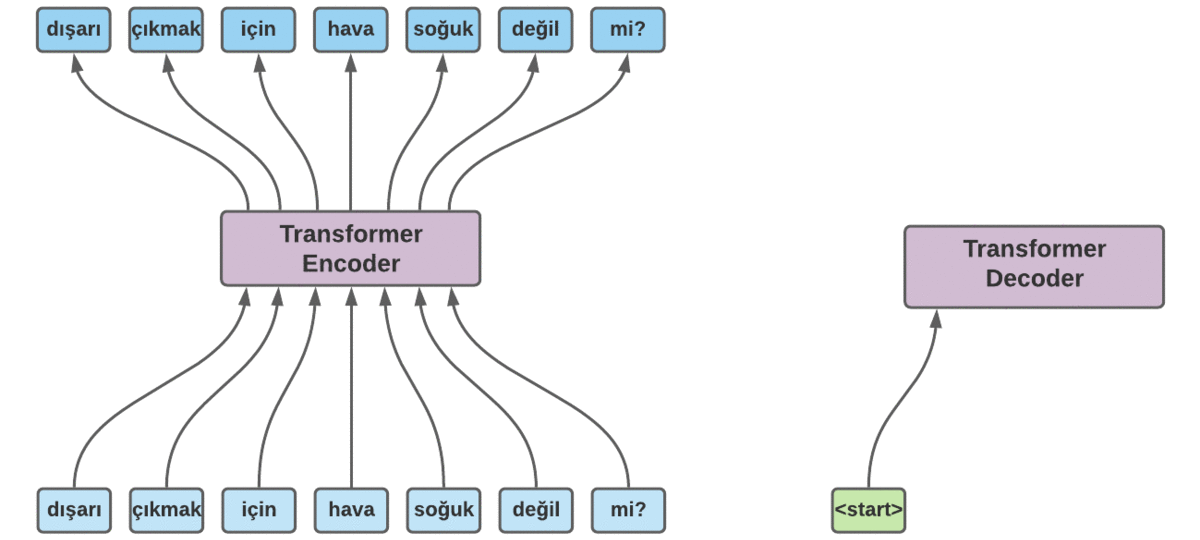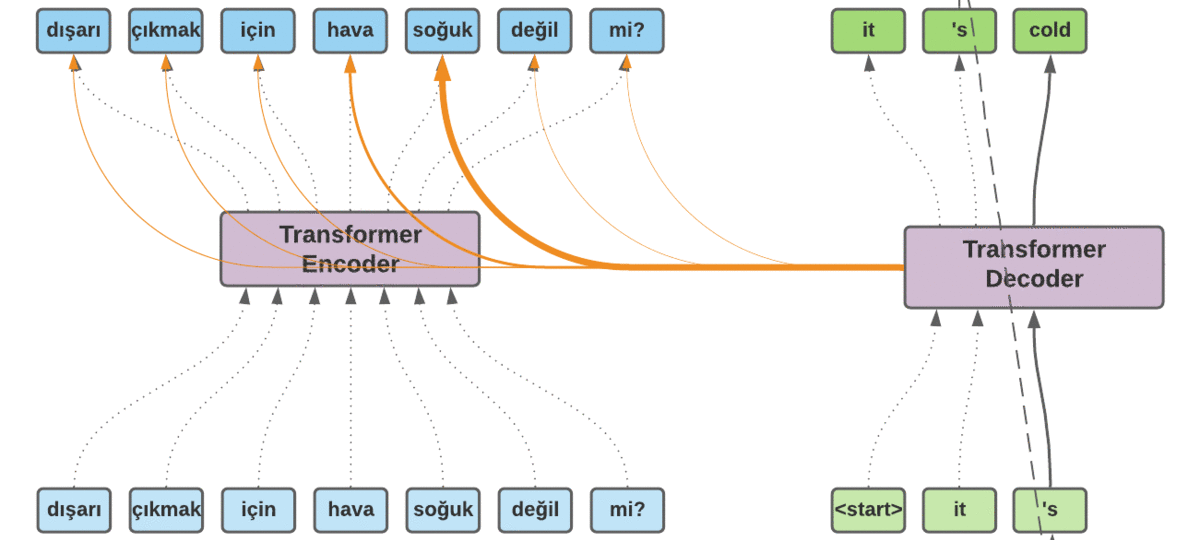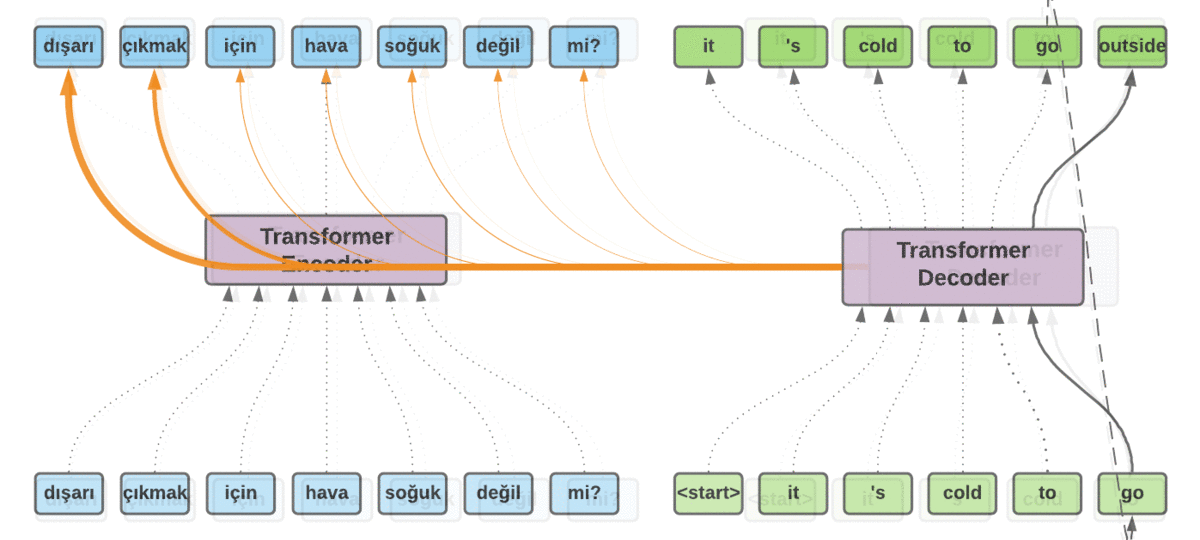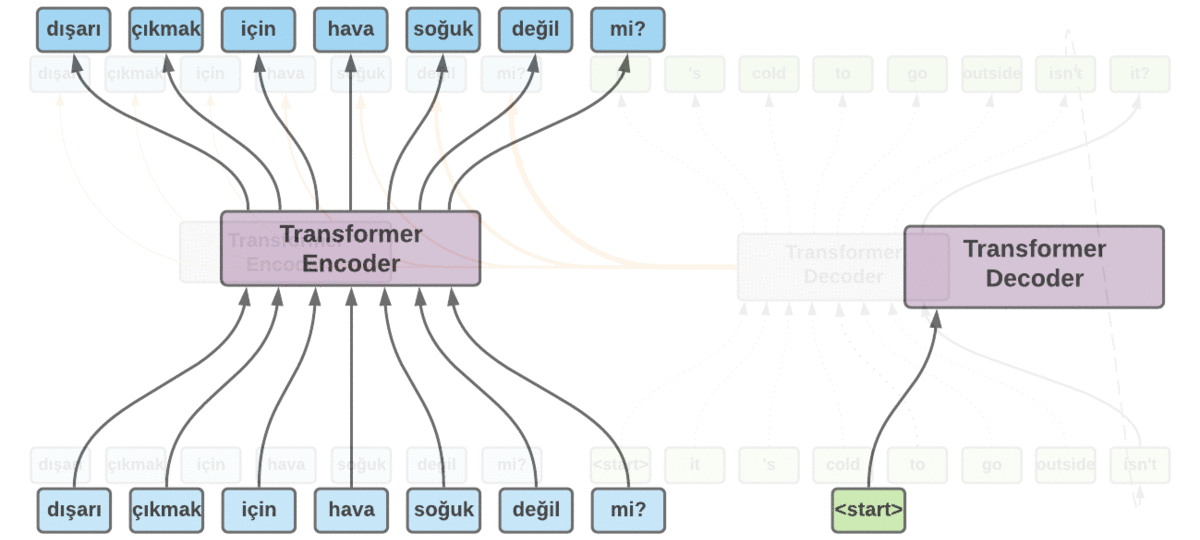
Mapa de atención
Ahora bien, ¿por qué el grosor de las flechas cambia en cada paso durante la traducción? Es una de las ventajas que tenemos con el mecanismo de atención. El aprendizaje profundo tiene muchos mecanismos internos que aún no se han explicado con claridad. La mayoría de los sistemas siguen considerándose cajas negras. Sabemos que son excelentes para extraer representaciones más complejas de alto nivel. Pero no estamos seguros de por qué se han decidido por algo en determinados casos. El mecanismo de atención alivia un poco este problema y aporta cierta interpretabilidad al modelo. En cada paso de la traducción, sabemos cuáles son los tokens de entrada que más han influido a la hora de generar el token en un paso concreto. Podemos utilizar esta información para extraer datos sobre la relación entre las palabras.

La figura 7 muestra el mapa de atención del ejemplo de traducción mostrado en la figura 6. Las columnas corresponden a la secuencia de entrada y las filas a la secuencia generada. Cada fila pertenece a un paso de tiempo específico. Por ejemplo, la cuarta fila que corresponde a «frío» se vio afectada principalmente por los tokens de entrada «hava soğuk». Como veremos en la sección de resultados, la arquitectura Transformer emplea múltiples cabezas de atención. Por lo tanto, acabamos teniendo múltiples mapas de atención.
Resultados
¿Cómo debemos evaluar un sistema de Traducción Automática Neuronal? Considere el famoso ejemplo «I made her duck». ¿Cómo se traduciría esta frase? He aquí algunas traducciones:
- Le cociné un pato.
- Cociné un pato que le pertenecía.
- He creado un pato (de juguete) para regalarle.
- La transformé en un pato. (magia)
- La hice agacharse (como verbo). (Había algo que se acercaba)
Lo que intento decir es que el lenguaje natural es ambiguo. Sería injusto esperar que las máquinas lo entendieran a la perfección, cuando incluso los humanos tienen dificultades para entenderse. Volviendo al problema, ¿Cómo se evaluaría esta traducción? El propio anotador es parcial y supone que en el momento de crear el conjunto de datos tenía hambre. Así que utilizó la primera frase para traducir la oración. Nuestro modelo, posteriormente, genera una de las otras opciones que son todas correctas porque aquí no conocemos el contexto. Aparentemente, la coincidencia exacta sería bastante ingenua, ya que incluso castigaría toda la traducción por una elección de palabra diferente. Como alternativa, la gente suele utilizar la puntuación BLEU (Bilingual Evaluation Understudy). Genera una puntuación entre [0,1], en algunos casos, la multiplicamos por 100 por comodidad. Utiliza n-gramas (1, 2, 3 y 4 principalmente) para evaluar la traducción con algunos trucos internos adicionales. Pero este mecanismo de evaluación puede fallar ligeramente también en este ejemplo. En general, la evaluación de un sistema NMT es un problema sutil y cabe esperar que un aumento de la puntuación BLEU no signifique necesariamente que la calidad de la traducción haya aumentado también. Los resultados de los experimentos realizados durante este proyecto se encuentran en la Tabla 1, en la que se compara un modelo seq2seq con GRU con el modelo Transformer. El conjunto de datos no contiene frases muy largas, por lo que la tarea es bastante fácil. Pero aún así, el modelo Transformer fue capaz de conseguir mejores resultados que el modelo de referencia incluso con la mitad del tamaño de los parámetros.

Experimentos
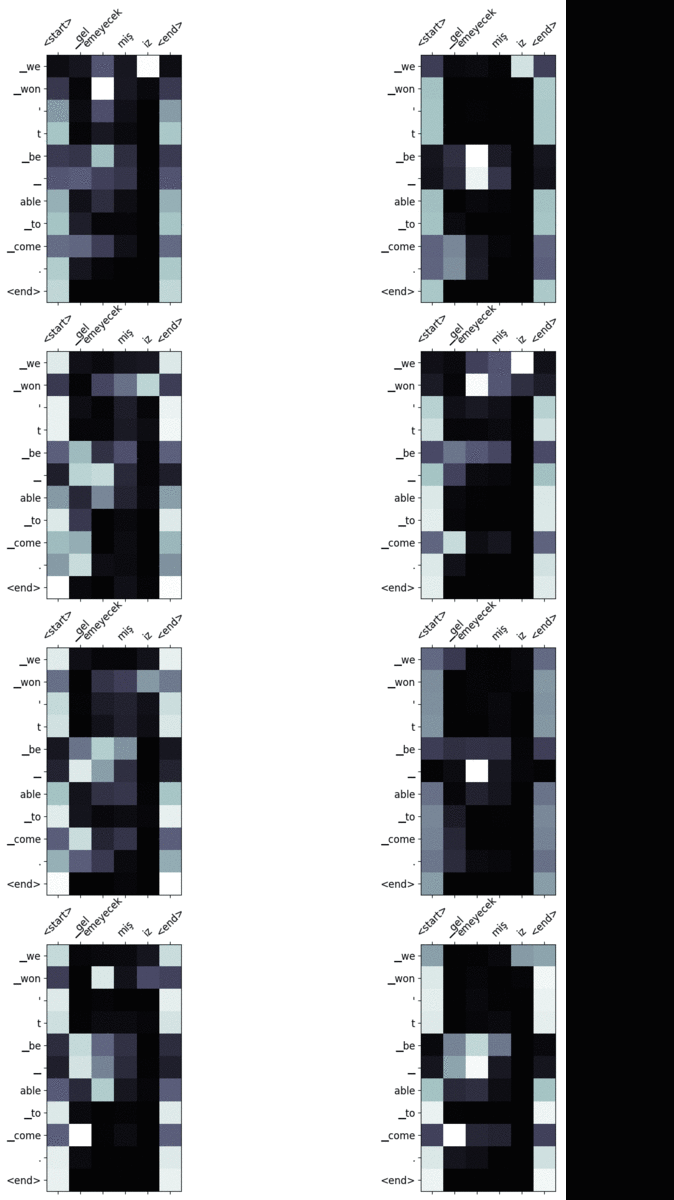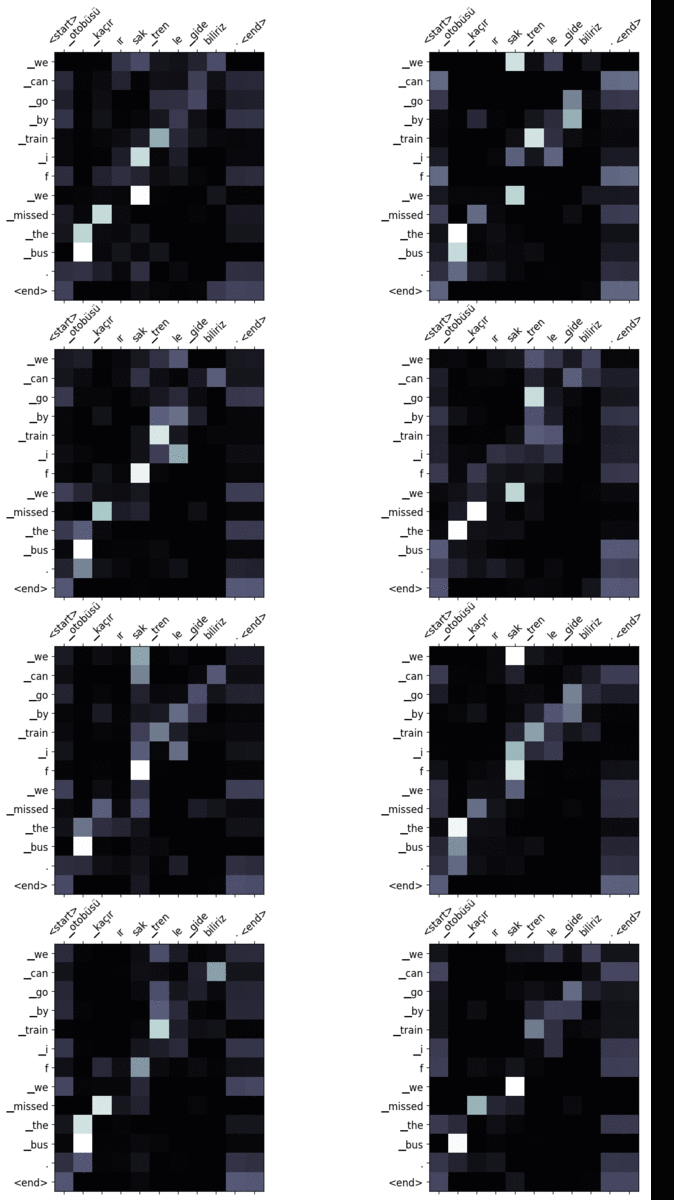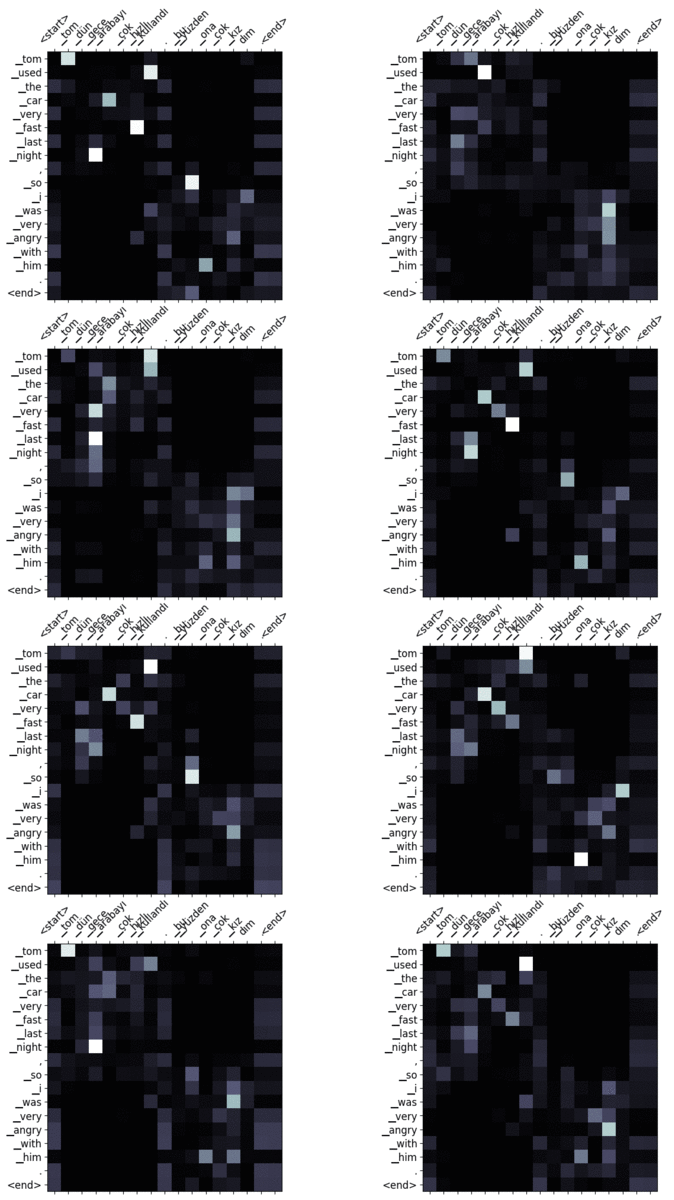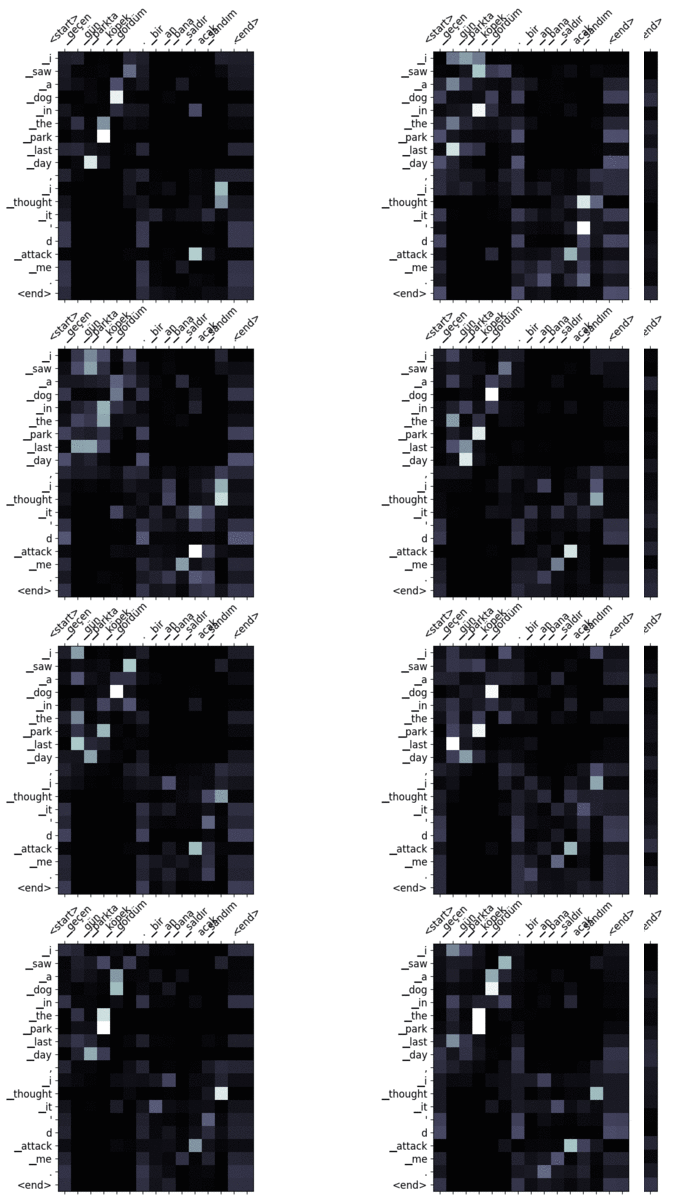
Aquí están algunos de los mapas de atención que he visualizado. Puedes mirar diferentes matrices para ver cómo el modelo gestiona la secuencia de entrada de diferentes maneras.
- Entrada: gelemeyecekmişiz.
Salida: no podremos venir. - Entrada: otobüsü kaçırırsak trenle gidebiliriz.
Salida: podemos ir en tren si perdemos el autobús. - Entrada: tom dün gece arabayı çok hızlı kullandı. ecel terleri döktüm
Output: tom usó el coche muy rápido anoche. derramé mucha mantequilla. 🙂 - Entrada: tom dün gece arabayı çok hızlı kullandı. bu yüzden ona çok kızdım.
Output: tom usó el coche muy rápido anoche, por lo que me enfadé mucho con él. - Entrada: geçen gün parkta köpek gördüm. bir an bana saldıracak sandım.
Output: el día pasado vi un perro en el parque, pensé que me atacaría.
No es fácil anotar todos los detalles de un artículo. Pero si este artículo te ha parecido interesante y quieres profundizar en el tema, la siguiente lista sería un buen punto de partida para empezar a leer:
- Documento Seq2seq de Sutskever et al. «Sequence-to-sequence learning with neural networks» [1].
- Mecanismo de atención de Bahdanau et al. «Neural machine translation by jointly learning to align and translate» [2].
- BPE y unidades de subpalabras por Sennrich et al. «Neural machine translation of rare words with subword units. «. [4].
- El transformador de Vaswani et al. «Attention is all you need » [3].
- Stanford CS224n: Natural Language Processing with Deep Learning
Entrenar un modelo NMT Transformer personalizado
Proporciono aquí el código fuente, el conjunto de datos utilizado, los tokenizadores y un modelo entrenado para que las personas interesadas en este tema puedan jugar con él. Puedes leer más detalles sobre cómo entrenar, evaluar y traducir en el repositorio https://github.com/azadyasar/NeuralMachineTranslation.
Conjunto de datos
Se ha utilizado un corpus paralelo inglés-turco como conjunto de datos. El conjunto de datos fue extraído del sitio web Tatoeba por [5]. El conjunto de datos consta de aproximadamente 500.000 pares de frases. Teníamos la idea de ampliar el tamaño del conjunto de datos utilizando los subtítulos de las películas. Pero no tuvimos suficiente tiempo para hacerlo. Para todos los experimentos, dividimos el conjunto de datos en conjuntos de entrenamiento, validación y prueba de un tamaño de 416.038, 46.227 y 51.363, respectivamente.
Como el conjunto de datos no es muy grande, se incluye dentro del repositorio en la carpeta data/. Al descomprimir el archivo, se obtienen tres archivos tsv correspondientes a los conjuntos de datos de entrenamiento, validación y prueba.
Codificación de pares de bytes tokenizadores
Estos tokenizadores son necesarios para tokenizar la secuencia de entrada y salida. También los proporcionamos dentro de la carpeta data/. Los archivos que terminan en .model son modelos de tokenizadores y los que terminan en .vocab contienen el vocabulario de un tokenizador específico. Si tienes un corpus más grande y relevante y quieres entrenar tus tokenizadores personalizados. Utilice el script train_bpe.py.
Entrenamiento
Aquí está el código para entrenar tu modelo personalizado. Detectará automáticamente si hay alguna GPU disponible y utilizará una disponible. De lo contrario, utilizará una CPU, lo cual no es recomendable.
python -m nmt train --train_dataset ../data/eng-tur-train.csv \
--eval_dataset ../data/eng-tur-val.csv \
--test_dataset ../data/eng-tur-test.csv \
--src_vocab ../data/tr_sp.model \
--trg_vocab ../data/en_sp.model \
--n_epochs 15 \
--hid_dims 256 \
--enc_layers 4 \
--dec_layers 4 \
--enc_heads 8 \
--dec_heads 8 \
--enc_pf_dim 1024 \
--dec_pf_dim 1024 \
--max_len 172 \
--lr 0.0005 \
--enc_dropout 0.35 \
--dec_dropout 0.35 \
--wd_rate 0.0001 \
--clip 1 \
--batch_sz 128 \
--save_model_path transformer_tr_en.pt
Código de entrenamiento
Debería ver los siguientes logs una vez que el modelo comience a entrenar sin problemas.

Evaluación y traducción
Puede evaluar el modelo entrenado con el siguiente código. Necesitamos los hiperparámetros del modelo para construirlo antes de cargarlo. Así que asegúrese de que coinciden con los reales.
python -m nmt evaluate --test_dataset ../data/eng-tur-test.csv \
--src_vocab ../data/tr_sp.model \
--trg_vocab ../data/en_sp.model \
--hid_dims 256 \
--enc_layers 4 \
--dec_layers 4 \
--enc_heads 8 \
--dec_heads 8 \
--enc_pf_dim 1024 \
--dec_pf_dim 1024 \
--max_len 172 \
--enc_dropout 0.35 \
--dec_dropout 0.35 \
--batch_sz 128 \
--model_path transformer_tr_en.pt
Use el siguiente código para traducir interactivamente las frases.
python -m nmt translate --src_vocab ../data/tr_sp.model \
--trg_vocab ../data/en_sp.model \
--hid_dims 256 \
--enc_layers 4 \
--dec_layers 4 \
--enc_heads 8 \
--dec_heads 8 \
--enc_pf_dim 1024 \
--dec_pf_dim 1024 \
--max_len 172 \
--enc_dropout 0.35 \
--dec_dropout 0.35 \
--model_path transformer_tr_en.pt
Cuando ejecute el script de traducción, se le pedirá que escriba una frase como se muestra a continuación:

Conclusión
Espero que este artículo haya sido útil e informativo. Pronto proporcionaré una nueva implementación del modelo RNN + Atención en el repositorio. Si encuentra algún error o en caso de que algo no cuadre, hágamelo saber para intentar corregirlo.
Referencias
- Ilya Sutskever, Oriol Vinyals y Quoc V Le. Sequence to sequence learning with neural networks. En Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, y K. Q. Weinberger, editores, Advances in Neural Information Processing Systems, volumen 27, páginas 3104-3112. Curran Associates, Inc., 2014.
- Dzmitry Bahdanau, Kyunghyun Cho y Yoshua Bengio. Neural machine translation by jointly learning to align and translate . CoRR, abs/1409.0473, 2015.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser e Illia Polosukhin.
Attention is all you need . En I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, y R. Garnett, editores, Advances in Neural Information Processing Systems, volumen 30, páginas 5998-6008. Curran Associates, Inc., 2017. - Rico Sennrich, Barry Haddow y Alexandra Birch.
Neural machine translation of rare words with subword units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), páginas 1715-1725, Berlín, Alemania, agosto de 2016. Asociación de Lingüística Computacional. - Jakob Uszkoreit.
Tab-delimited bilingual sentence pairs http://www.manythings.org/anki/, 30 de enero de 2021. - NMT Transformer Implementation : https://github.com/azadyasar/NeuralMachineTranslation
Articulos relacionados

Traducción a Español de un artículo en Inglés de Some Aditya Mandal donde se explican los esfuerzos de los investigadores que hicieron avanzar la Traducción Automática Estadística hasta la actual Traducción Automática Neuronal.
Traducción a Español de un artículo de Azad Yaşar, explicando los nuevos modelos Seq2Seq de Traducción Automática Neuronal, capaces de mapear y trazar relaciones entre 2 idiomas en base a un corpus paralelo.

Traducción a Español de un artículo en Ingles de Arslan Mirza explicando las ventajas y limitaciones de la Traducción Automática, ante los cambios constantes de la información.