Breve historia de la Traducción Automática (MT)
Traducción a Español de un artículo en Inglés de Teven Le Scao explicando los paradigmas y la evolución histórica de la Traducción Automática (MT): desde sus orígenes en 1933, y la posterior Traducción Automática basada en reglas, hasta la Traducción Automática basada en datos, y la actual Traducción Automática Neuronal.
 10 junio, 2021 Primera traducción automática Ruso - Inglés, en 1954.
10 junio, 2021 Primera traducción automática Ruso - Inglés, en 1954.Texto original escrito por Teven Le Scao y publicado el 14/05/2020 en https://medium.com/huggingface/a-brief-history-of-machine-translation-paradigms-d5c09d8a5b7e
Como joven europeo, tener acceso a una traducción en cualquier momento con sólo sacar mi teléfono, es un lujo sin precedentes. Es super cómodo saber que puedo pedir un kebab en cien idiomas, cu de tuate und scharf, bez příliš mnoho cibule mais avec frites, y hay algo especial en poder hacerlo incluso en países que en generaciones anteriores estaban en conflicto con la mía. Esto hizo que la traducción automática fuera mi primer amor entre las aplicaciones de Machine Learning: es la razón por la que originalmente pasé de las matemáticas aplicadas a la PNL. Esta semana, Hugging Face se enorgullece de publicar más de 1000 modelos de traducción de la Universidad de Helsinki, gracias al duro trabajo de Jörg Tiedemann, de Helsinki, y de nuestro propio Sam Shleifer. Para acompañar el lanzamiento, he aquí una breve historia de los esfuerzos de traducción automática en el último siglo. Está escrita pensando en un público familiarizado con la PNL moderna, y he intentado establecer conexiones con otros campos.
Disclaimer: Este es un ejercicio de traducción realizado por un estudiante de traducción en prácticas. Si lo que necesitas son servicios de traducción profesional realizados o al menos revisados por traductores humanos, contacta con la agencia de traducción Ibidem Group. Consulta los servicios de Machine Translation y PEMT. Contacta con cualquiera de sus oficinas. Ibidem Group Traducciones Barcelona. Ibidem Group traducciones Madrid.
INDICE
1. Orígenes de la Traducción Automática (1933-1945)
Los primeros sistemas de Traducción Automática (MT) fueron creados de forma independiente en 1933, por George Artsrouni en Francia¹ y Petr Troyanskii en la URSS². Desgraciadamente, ninguno de los dos se impuso realmente en los círculos de la ingeniería o la investigación, por diferentes razones. El sistema de Artsrouni, que era un sistema de recuperación mecánica automatizada que podía funcionar como un diccionario, suscitó mucho interés en la administración francesa, pero no pudo llegar a buen puerto antes del comienzo de la Segunda Guerra Mundial. El sistema de Troyanskii, que también empezó como un diccionario automatizado pero que llegó a incorporar una memoria y componentes electrónicos (¡en aquella época todavía eran ordenadores mecánicos!) fue ignorado por el estamento científico soviético.
En otros lugares de Europa se produjeron al mismo tiempo acontecimientos que tendrían un impacto ligeramente superior. Entre 1932 y 1933, la Oficina Polaca de Cifrado -sobre todo Marian Rejewski, que da nombre al sistema Marian NMT- descifró el código de las primeras máquinas Enigma alemanas. Durante la propia Segunda Guerra Mundial, la criptografía se convirtió en un tema clave y movilizó importantes recursos intelectuales y financieros. Una vez terminada la guerra, con el aumento de la guerra fría, la Traducción Automática se convirtió en un tema de interés para las comunidades de inteligencia de ambas superpotencias. Un problema clave, por ejemplo, era la Traducción Automática de artículos científicos del otro bando, ya que la producción científica superaba el número de traductores competentes.
En este contexto, el memorando Weaver de 1949 sobre la traducción⁴ marcó un hito en EE.UU., al defender que la Traducción Automática estaba siendo posible gracias al recién creado ordenador. En él se proponían varios enfoques, como el almacenamiento de las reglas del lenguaje en la máquina o el aprendizaje de las similitudes estadísticas entre las frases, con una mención incluso a los primeros esfuerzos sobre los perceptrones. Resulta muy llamativa la filiación directa que establece entre la Traducción Automática y los esfuerzos de criptografía en tiempos de guerra: se abre con una anécdota bélica y plantea la tarea de traducir el ruso como si fuera un código.
Cuando miro un artículo en ruso, me digo: ‘Esto está realmente escrito en inglés, pero ha sido codificado con unos símbolos extraños. Ahora procederé a descodificarlo».
No hay nada como una buena rivalidad entre grandes potencias para la financiación de la investigación.
2. Traducción Automática basada en reglas (1949-1984)
La primera MT basada en reglas (1949-1967)
Tras la publicación del Memorándum Weaver, la investigación sobre la Traducción Automática comenzó en serio en Estados Unidos, centrada sobre todo en la traducción de artículos científicos rusos al inglés. Los sistemas de traducción de la época pueden situarse generalmente en una escala entre los enfoques empíricos y los lingüísticos. Por ejemplo, en el extremo empírico de la escala, la investigación en la corporación RAND procedía en ciclos de traducción y edición. Primero, se parte de unas pocas reglas básicas, observando el resultado en un corpus predeterminado de textos rusos. Después, revisar el glosario y las reglas gramaticales del sistema, y repetir el ciclo, en una especie de algoritmo de maximización de expectativas realizado por humanos (¿tal vez un ancestro de la ascendencia de los estudiantes de posgrado? ) Por otro lado, la investigación académica, especialmente en el MIT, se centró en la búsqueda de representaciones intermedias entre las frases de origen y las de destino. Se esperaba que unas representaciones suficientemente expresivas permitieran una traducción de propósito general. Otro objetivo era construir una interlingua, es decir, una representación del significado semántico independiente de la lengua; Noam Chomsky estaba introduciendo la gramática universal al mismo tiempo⁵.
En 1954 se demostró en la Universidad de Georgetown un sistema híbrido para traducir documentos técnicos rusos. Considerado muy impresionante en su momento, estimuló la inversión en Estados Unidos y sembró el interés en otros lugares, sobre todo en la Unión Soviética y en Europa, donde la investigación se concentró en el enfoque teórico. Los sistemas de la época se basaban en el trabajo de amplios equipos de lingüistas: traducían las instrucciones humanas al código en lugar de aprender las correspondencias de las palabras por sí mismos.
MT basada en el conocimiento (1967-1984)
El informe ALPAC de 1967⁶ se considera generalmente el final de la primera fase de la traducción automática, después de haber defendido que la financiación de la investigación estadounidense debería dirigirse a la traducción humana asistida por máquina en lugar de a la traducción automática completa. Tras su publicación, la financiación de la investigación se agotó en Estados Unidos, dejando los esfuerzos de investigación en traducción automática en Canadá y Europa, y en la Unión Soviética.
Ya hemos señalado que, si bien disponemos de traducción automática de textos científicos generales, no tenemos una traducción automática útil. Además, no hay perspectivas inmediatas ni previsibles de que la traducción automática sea útil.
El clásico revisor #2.
Un concepto influyente para entender la evolución de la MT basada en reglas durante ese tiempo es la pirámide de Vauquois, reproducida aquí. En primer lugar, el sistema intenta comprender el texto de origen (análisis) y representar esta comprensión. A continuación, produce un texto en la lengua de destino (generación) a partir de esta representación. Esto se bautizó como TA basada en el conocimiento: el objetivo era disponer de representaciones cada vez más completas y generales, ascendiendo en la pirámide, frente a la traducción directa de los sistemas anteriores basados en reglas o a la traducción sólo informada sintácticamente. Sin embargo, la traducción automática por transferencia, que operaba a un nivel inferior, seguía siendo más eficaz y potenciaba los sistemas de la época. Se trataba, sobre todo, de casos de uso técnico limitados al dominio, como el sistema Météo de Canadá.
3. Traducción Automática basada en datos (1984-hoy)
MT basada en ejemplos (1984-1993)
En la década de 1980, los ordenadores se habían vuelto mucho más potentes, sobre todo en cuanto a capacidad de almacenamiento. Esto permitía disponer de bases de datos de texto más grandes, que aún no se habían explotado de forma sistemática. Una de las primeras ideas para hacerlo fue la MT basada en ejemplos, que se propuso por primera vez en 1984 en Japón⁷. Los sistemas basados en ejemplos partieron de la observación de que los hablantes de lenguas extranjeras de nivel principiante se basan en frases que ya conocen para producir otras nuevas: en la figura se muestra un ejemplo entre el francés y el inglés⁸. Del mismo modo, se basaban en bases de datos de ejemplos conocidos para producir nuevas traducciones, consultando la más cercana. Aunque estas ideas acabarían subsumiéndose en el marco más amplio de la MT estadística, fueron el primer ejemplo de traducción basada en datos.
MT estadística (1993-2013)
Por debajo de todo esto, se estaba gestando una revolución, ya que en la década de los 90 se produjeron algunos avances externos. El reconocimiento estadístico del habla empezó a dar buenos resultados gracias a los avances en la teoría de los autómatas y los modelos ocultos de Markov; los ordenadores se volvieron más potentes y accesibles y aparecieron conjuntos de datos abundantes y de gran calidad, como las cuentas Hansards del parlamento canadiense. En 1988, los investigadores de IBM publicaron el esquema de la traducción estadística moderna⁹, que resultó, como mínimo, controvertido. Como dice una famosa reseña anónima de la época:
La validez de un enfoque estadístico (teórico de la información) de la MT ha sido reconocida, como mencionan los autores, por Weaver ya en 1949. Y fue reconocida universalmente como errónea en 1950 (cf. Hutchins, MT – Past, Present, Future, Ellis Horwood, 1986, p. 30ff y sus referencias). La fuerza bruta de los ordenadores no es ciencia. Simplemente, está fuera del alcance de COLING.
El revisor nº 2 ataca de nuevo.
Sin embargo, el enfoque estadístico no tardó en resultar fructífero, ya que los modelos 1-5 de IBM se convirtieron en referencias de la traducción automática. Estos modelos se basaban en el algoritmo de maximización de expectativas para aprender tanto los alineamientos entre idiomas -cuáles y cuántas palabras del origen y del destino se corresponden- como un diccionario para traducir después de calcular los alineamientos. En cierto sentido, eran descendientes directos del primer enfoque empírico de RAND: en lugar de recibir instrucciones de equipos de lingüistas, el ordenador podía aprender todas las relaciones a partir de los datos por sí mismo. En la década de 2010, los métodos estadísticos habían afirmado su hegemonía, ya que impulsaban prácticamente todos los servicios de traducción basados en Internet que constituyen la mayor parte del uso de la traducción.
MT neuronal (2013-hoy)
En su memorándum de 1949, Warren Weaver se refiere brevemente a las primeras investigaciones sobre el perceptrón como una vía prometedora para la Traducción Automática. 60 años más tarde, las redes neuronales habían logrado avances significativos en otras tareas, pero aún no se habían aplicado de forma convincente a la traducción. Los primeros modelos neuronales funcionales del lenguaje aparecieron en 2011, impulsados por redes neuronales recurrentes¹⁰. La traducción pudo entonces reformularse como una tarea de modelado lingüístico condicional: en lugar de predecir la siguiente palabra más probable, predecir la siguiente palabra más probable condicionada al texto de origen. El primer trabajo moderno de traducción automática apareció a los pocos años, en 2013. Consistía en un modelo codificador que producía una representación de la entrada con una red neuronal convolucional y en un modelo decodificador que generaba el texto a partir de esa representación con una red neuronal recurrente de vainilla (RNN)¹¹.
En aquel momento, la MT neural seguía teniendo un rendimiento inferior al de la MT estadística, y necesitó dos desarrollos principales a partir de 2014 para acabar imponiéndose. En primer lugar, se sustituyeron las RNN de vainilla por las RNN de memoria a corto plazo (LSTM)¹². A continuación, se reutilizaron los mecanismos de atención aprendible de sus raíces de visión por ordenador y se añadieron a las LSTM¹³. En 2016, Google Translate se pasó a la MT neural. Los modelos basados en transformadores¹⁴, que eliminan la parte de la red recurrente y solo utilizan módulos de atención iterada, se han convertido en la norma en los últimos años, ya que se adaptan mejor que las LSTM al tiempo de cálculo y a los datos disponibles. Todos los modelos de Helsinki que publicamos hoy se basan en esta arquitectura. La potencia de los transformadores se hizo notar rápidamente fuera de la traducción automática y, combinados con el preentrenamiento, forman ahora la columna vertebral de la mayoría de las aplicaciones modernas de PNL.
Conclusión
La Traducción Automática tiene 3 objetivos básicos: alcanzar la calidad de traducción humana (es decir, de traductores profesionales humanos) nativos, traducción genérica y traducción sin input humano. Los antiguos sistemas basados en el conocimiento podían realizar traducciones con la calidad de un traductor nativo, pero sólo con datos muy limitados. Los sistemas «human-in-the-loop» hacían una traducción profesional más rápida, pero requerían la intervención manual. Por último, la traducción estadística podía manejar cualquier texto sin un ser humano, pero no siempre al nivel de los traductores humanos. Si tiene la suerte de tener que traducir entre lenguas similares con muchos datos, la MT neural ofrece lo mejor de todos los mundos. Sin embargo, si el par de idiomas que le interesa no es rico en datos, todavía queda bastante trabajo por hacer antes de llegar a ese punto. Un proyecto interesante para darse cuenta de la magnitud de la tarea es el programa Lorelei de DARPA, que simula una crisis en una región del mundo cuya lengua está desatendida, y pide a los investigadores que construyan un sistema de traducción en dos semanas. Incluso en el caso de las lenguas habladas por decenas de millones de personas, a veces hay que recurrir a equipos de lingüistas altamente cualificados para resolver el problema.
Referencias
1] «La machine à traduire française aura bientôt trente ans», Automatisme 5(3): 87-91, M. Corbé, 1960
2] Traducción automática: pasado, presente y futuro. J. Hutchins, 1986
3] Foto de la estatua de Marian Rejewski de Peter Reed
4] Reproducido en: Locke, W.N.; Booth, D.A., eds. (1955). «Translation» (PDF). Machine Translation of Languages. Cambridge, Massachusetts: MITPress. pp. 15-23. ISBN 0-8371-8434-7.
5] Aspectos de la teoría de la sintaxis, Noam Chomsky, 1965
6] LENGUAJE Y MÁQUINAS: LOS ORDENADORES EN LA TRADUCCIÓN Y LA LINGÜÍSTICA, ALPAC 1966
7] Marco para una traducción mecánica entre el japonés y el inglés por principio de analogía, Nagao 1984
8] Figura de EBMT de Purest ever example-based machine translation: detailed presentation and assessment, Y. Lepage, E. Denoual, Machine Translation, Springer Verlag, 2007, pp.251-282. hal-00260994
9] A Statistical Approach to Language Translation, P. Brown, J. Cocke, S. Della Pietra, V. Della Pietra, F. Jelinek, R. Mercer, P. Roosin, COLING, 1988.
10] RNNLM -Recurrent Neural Network Language Modeling Toolkit, T. Mikolov, S. Kombrink, A. Deoras, L. Burget, J. Černocký, 2011
11] Modelos recurrentes de traducción continua, N. Kalchbrenner, P. Blunsom, 2013
12] Aprendizaje secuencia a secuencia con redes neuronales, I. Sutskever, O. Vinyals, Q. Le, 2014
13] Traducción automática neuronal mediante el aprendizaje conjunto de la alineación y la traducción, D. Bahdanau, K. Cho, Y. Bengio, 2014
14] Attention Is All You Need, A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. Gómez, L. Kaiser, I. Polosukhin, 2017
Articulos relacionados
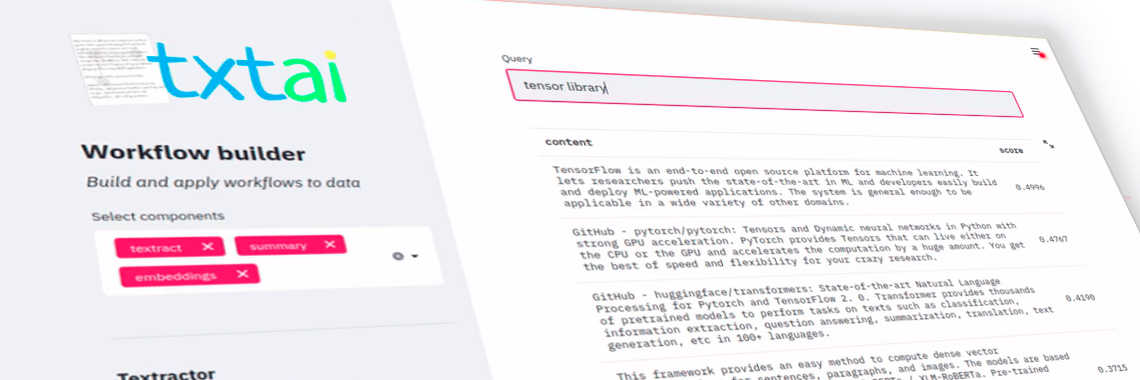
Traducción automática respaldada por modelos Hugging Face en el motor de búsqueda Txtai (AI). Un texto original de David Mezzeti, traducido aquí a Español.
Traducción a Español de un artículo en Inglés de Teven Le Scao explicando los paradigmas y la evolución histórica de la Traducción Automática (MT): desde sus orígenes en 1933, y la posterior Traducción Automática basada en reglas, hasta la Traducción Automática basada en...